Wie in den vorhergehenden Aufgaben bereits angesprochen, erfordert eine
ereignisgesteuerte Behandlung von Ereignissen explizite Synchronisation
zwischen den verschiedenen Ereignisbehandlungen, um z.B. den gegenseitigen
Ausschluss innerhalb kritischer Bereiche sicherzustellen. Alle Dinge, die
explizit vom Entwickler berücksichtigt werden müssen, sind aber
potentielle Fehlerquellen, so auch die Synchronisation. Im Folgenden sollen
einige Fehlerszenarien beschrieben werden:
Fehlende Synchronisation
Ein vergleichsweise banaler, aber sehr schwer zu entdeckender Fehler ist
die fehlende Synchronisation eines kritischen Abschnitts. Dieser Fehler wird
erst dann bemerkt, wenn aufgrund des fehlenden gegenseitigen Ausschlusses eine
Datenstruktur korrumpiert wurde und dies zu einem Folgefehler führt. Zu
diesem Zeitpunkt ist es oft schwer nachzuvollziehen, wo der eigentliche Fehler
liegt, und eine Behebung des Fehlers zeitaufwendig.
Prioritätenumkehr (engl. Priority Inversion)
Ein vor allem für Echtzeitsysteme schwerwiegender Fehler ist die
sogenannte Prioritätenumkehr, insbesondere wenn es sich um eine
unkontrollierte Prioritätenumkehr handelt. Unter Prioritätenumkehr
versteht man im Allgemeinen den Zustand, dass eine Ereignisbehandlung mit
niedrigerer Priorität eine Ereignisbehandlung höherer Priorität
blockiert, weil ein gemeinsames, nur exklusiv nutzbares Betriebsmittel belegt
wird. Im Falle einer unkontrollierten Prioritätenumkehr wird die
nieder-priore Ereignisbehandlung zusätzlich noch von min. einer
Ereignisbehandlung mittlerer Priorität verdrängt und kann deshalb
das Betriebsmittel nicht wieder freigeben. Die höher-priore
Ereignisbehandlung wird hier auf unbestimmte Zeit blockiert. Die genaue
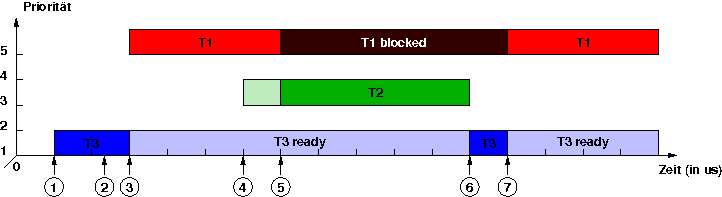
Abfolge wird in der folgenden Grafik erklärt:
Der nieder-priore Thread T3 wird gestartet.
Der nieder-priore Thread T3 belegt das Betriebsmittel m.
Der hoch-priore Thread T1 verdrängt den nieder-prioren Thread T3.
Der mittel-priore Thread T2 wird ausgelöst, aber noch nicht ausgeführt, weil sich mit Thread T1 eine höher-priorer Thread in Ausführung befindet.
Der hoch-priore Thread T1 versucht das Betriebsmittel m zu belegen, dieses ist aber bereits belegt, der hoch-priore Thread T1 blockiert und der mittel-priore Thread T2 wird ausgeführt.
Der mittel-priore Thread T2 beendet sich und der nieder-priore Thread T1 wird ausgeführt.
Der nieder-priore Thread T3 gibt das Betriebsmittel m wieder frei, der hoch-priore Thread T1 belegt nun das Betriebsmittel und wird ausgeführt.
In diesem Szenario verhindert der mittel-priore Thread T2,
dass der nieder-priore Thread T3 das Betriebsmittel
m wieder freigibt und blockiert so indirekt den hoch-prioren
Thread T1. Die Dauer der Blockade hängt in diesem Fall
ausschließlich von der Ausführungszeit von T2 ab.
Verklemmungen (engl. Deadlocks bzw. Lifelocks)
Deadlocks können entstehen, wenn zwei Ereignisbehandlungen
wechselseitig Betriebsmittel anfordern, die von der jeweils anderen
Ereignisbehandlung bereits belegt sind, also ein Zyklus im sogenannten
Wartegraphen entsteht. Zusätzlich dürfen die Betriebsmittel nur
exklusiv belegbar sein und die Primitive zum Belegen von Betriebsmitteln
müssen eine blockierende Semantik aufweisen. Lifelocks
können entstehen, wenn eine Ereignisbehandlung z.B. aktiv auf das
Eintreten eines Ereignisses wartet, und das Ereignis durch das aktive Warten
blockiert wird. In beiden Fällen macht das System keinen
Fortschritt mehr, bei Deadlocks ist dies explizit erkennbar, bei
Lifelocks jedoch nicht. Von den Alternativen Erkennung
(engl. Deadlock Detection), Vermeidung (engl. Deadlock
Avoidance) und Vorbeugung (engl. Deadlock Prevention)
für den Umgang mit Deadlocks ist in der Praxis, insbesondere
für Echtzeitsysteme, die Vorbeugung der einzig praktikable Weg. Die
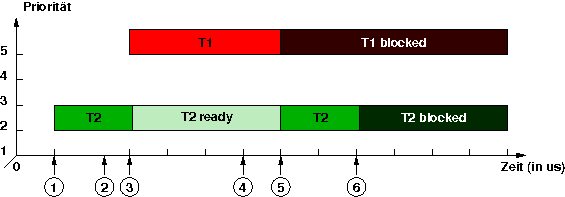
Entstehung eines Deadlocks veranschaulicht folgende Grafik:
Der nieder-priorer Thread T2 wird gestartet.
Der nieder-priorer Thread T2 belegt das Betriebsmittel m1.
Der nieder-priorer Thread T2 wird vom höher-prioren Thread T2 verdrängt.
Der höher-priore Thread T1 belegt das Betriebsmittel m2.
Beim Versuch, das Betriebsmittel m1 zu belegen, blockiert der höher-priore Thread T1, weil das Betriebsmittel bereits vom nieder-prioren Thread T2 belegt wurde. Der nieder-priorer Thread T2 wird weiter ausgeführt.
Beim Versuch, das Betriebsmittel m2 zu belegen, blockiert der nieder-priore Thread T2, weil das Betriebsmittel bereits vom höher-prioren Thread T1 belegt wurde. Ein Deadlock ist die Folge.
Die an einem Deadlock beteiligten Fäden haben keine Möglichkeit, sich selbst aus diesem Deadlock zu befreien!
Lösung
Für fehlende Synchronisationsprimitive gibt es keinen Mechanismus, der
so enstandene Fehler auffangen könnte, solche Situationen sind schlicht
und ergreifend Fehler im Programm. Für unkontrollierte
Prioritätenumkehr und Deadlocks gibt es Synchronisationsprimitive, die
mit speziellen Protokollen behaftet sind und diese Phänomene von
vornherein verhindern.
Prioritätsvererbung (engl. Priority Inheritance)
Mit Hife der Prioritätsvererbung kann eine unkontrollierte
Prioritenumkehr ausgeschlossen werden. Dieses Protokoll ist für die
weitere Bearbeitung der Aufgabe nicht von Bedeutung und wurde in der Vorlesung
bereits behandelt. Auf eine nähere Erläuterung wird daher
verzichtet.
Prioritätsobergrenzen (engl. Priority Ceiling)
Prioritätsobergenzen schließen unkontrollierte Prioritätenumkehr und
Deadlocks von vornherein aus. Hierfür wird für jedes Betriebsmittel eine
Prioritätsobergrenze bestimmt, die gleich der Priorität der höchst-prioren
Ereignisbehandlung ist, die dieses Betriebsmittel belegen möchte. Belegt nun
eine Ereignisbehandlung erfolgreich ein Betriebsmittel, so wird die
systemweite Prioritätsobergrenze auf die Prioritätsobergrenze dieses
Betriebsmittels gesetzt. Versucht eine höher-priore Ereignisbehandlung ein
Betriebsmittel zu belegen, das bereits belegt ist, erbt die besitzende
Ereignisbehandlung die Prioritätsobergrenze dieses Betriebsmittels. Auf diese
Weise wird einer unkontrollierten Prioritätenumkehr vorgebeugt. Zusätzlich ist
auf alle Betriebsmittel noch eine lineare Ordnung definiert (eine
Ereignisbehandlung darf ein Betriebsmittel nur dann belegen, wenn dieses
Betriebsmittel eine höhere Prioritätsobergrenze besitzt, als die derzeitige
systemweite Prioritätsobergrenze - Ausnahme: die Ereignisbehandlung belegt
bereits das Betriebsmittel, das die aktuelle systemweite Prioritätsobergrenze
bedingt), so werden Deadlocks verhindert. Ein Beispiel für die Arbeitsweise
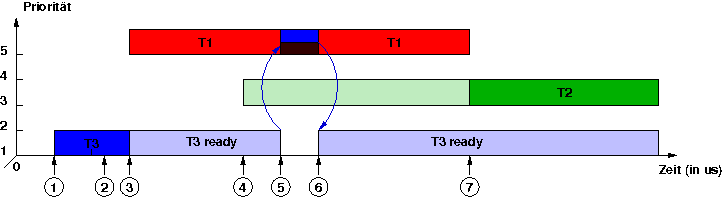
der Prioritätsobergrenzen ist in der untenstehenden Grafik abgebildet. Die
Threads T1 und T3 wollen beide auf das
Betriebsmittel m zugreifen, dessen Prioritätsobergrenze ist daher
die Priorität des höher-prioren Threads T1.
Der nieder-priore Thread T3 wird gestartet.
Der nieder-priore Thread T3 belegt das Betriebsmittel m.
Der hoch-priore Thread T1 verdrängt den nieder-prioren Thread T3.
Der mittel-priore Thread T2 wird ausgelöst, aber noch nicht ausgeführt, weil sich mit Thread T1 eine höher-priorer Thread in Ausführung befindet.
Der hoch-priore Thread T1 versucht das Betriebsmittel m zu belegen, dieses ist aber bereits belegt, der hoch-priore Thread T1 blockiert, der nieder-priore Thread T3 erbt die Prioritätsobergrenze des Betriebsmittels m und wird daher ausgeführt.
Der nieder-priore Thread T3 gibt das Betriebsmittel m wieder frei und fällt auf seine ursprüngliche Priorität zurück. Der hoch-priore Thread T1 belegt nun das Betriebsmittel und wird ausgeführt.
Der hoch-priore Thread T1 beendet sich und der mittel-priore Thread T2 wird ausgeführt.
In dieser Aufgabe soll ein Mutex entwickelt werden, der das sogenannte
OSEK Priority Ceiling Protocol implementiert. Dieses Protokoll ist
ein Abkömmling des sogenannten Stack Based Priority Ceiling
Protocol. Dieses Protokoll will die Verwendung eines einzigen
Stapelspeichers für alle Ereignisbehandlungen trotz Synchronisation
ermöglichen. Dazu ist es notwendig, dass keine Ereignisbehandlung
blockiert, die Belegung eines Betriebsmittels also immer erfolgreich sein
muss. Die Funktionsweise dieses Protokolls wird nun stichpunktartig
erläutert:
Jedem Mutex wird eine Prioritätsobergrenze zugeordnet, die Prioritätsobergrenze ist gleich der Priorität des höchst-prioren Fadens, der diesen Mutex belegen will.
Belegt ein Faden einen Mutex, so erbt dieser Faden unmittelbar dessen Prioritätsobergrenze und wird mit dieser Priorität ausgeführt.
Ein Faden darf nur solche Mutexes belegen, deren Prioritätsobergrenze mindestens so hoch wie die gegenwärtige Priorität des Fadens ist.
Gibt ein Faden einen Mutex wieder frei, so fällt der Faden wieder auf die Priorität zurück, die dieser Faden vor dem Belegen des Mutex inne hatte.
Ein Faden muss zuerst immer den Mutex freigeben, den er zuletzt belegt hat.
Wenn ein Faden einen Mutex belegt, wird dies also immer erfolgreich
verlaufen, weil dieser Faden ansonsten nicht ausgeführt werden
würde. Wäre der Mutex schon von einem anderen Faden belegt worden,
hätte dieser ja bereits die Prioritätsobergrenze des Mutex geerbt
und kein anderer Faden, der diesen Mutex belegen will, könnte
ausgeführt werden. Um die korrekte Funktionsweise dieses Protokolls zu
gewährleisten, darf ein Faden, der einen oder mehrere Mutexes belegt, die
Kontrolle über den Prozessor aber nicht abgeben, d.h. der Faden darf
nicht yield() oder sonstige blockierende Primitive aufrufen. Das
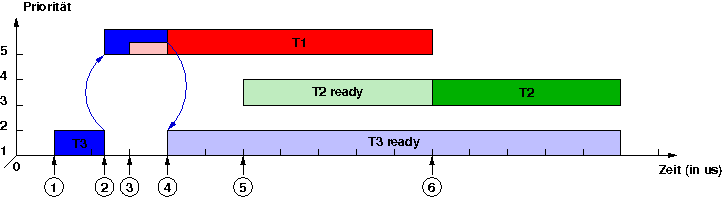
folgende Beispiel veranschaulicht diesen Mechanismus und verdeutlicht den
Unterschied zu herkömmlichen Prioritätsobergrenzen:
Der nieder-priore Thread T3 wird gestartet.
Der nieder-priore Thread T3 belegt das Betriebsmittel m und erbt dessen Prioritätsobergrenze.
Der hoch-priore Thread T1 wird ausgelöst, aber nicht ausgeführt, da der nieder-priore Thread T3 mit der Prioritätsobergrenze des Betriebsmittels m ausgeführt wird.
Der nieder-priore Thread T3 gibt das Betriebsmittel m wieder frei und fällt auf seine ursprüngliche Priorität zurück. Der hoch-priore Thread T1 belegt nun das Betriebsmittel und wird ausgeführt.
Der mittel-priore Thread T2 wird ausgelöst, aber noch nicht ausgeführt, weil sich mit Thread T1 eine höher-priorer Thread in Ausführung befindet.
Der hoch-priore Thread T1 beendet sich und der mittel-priore Thread T2 wird ausgeführt.
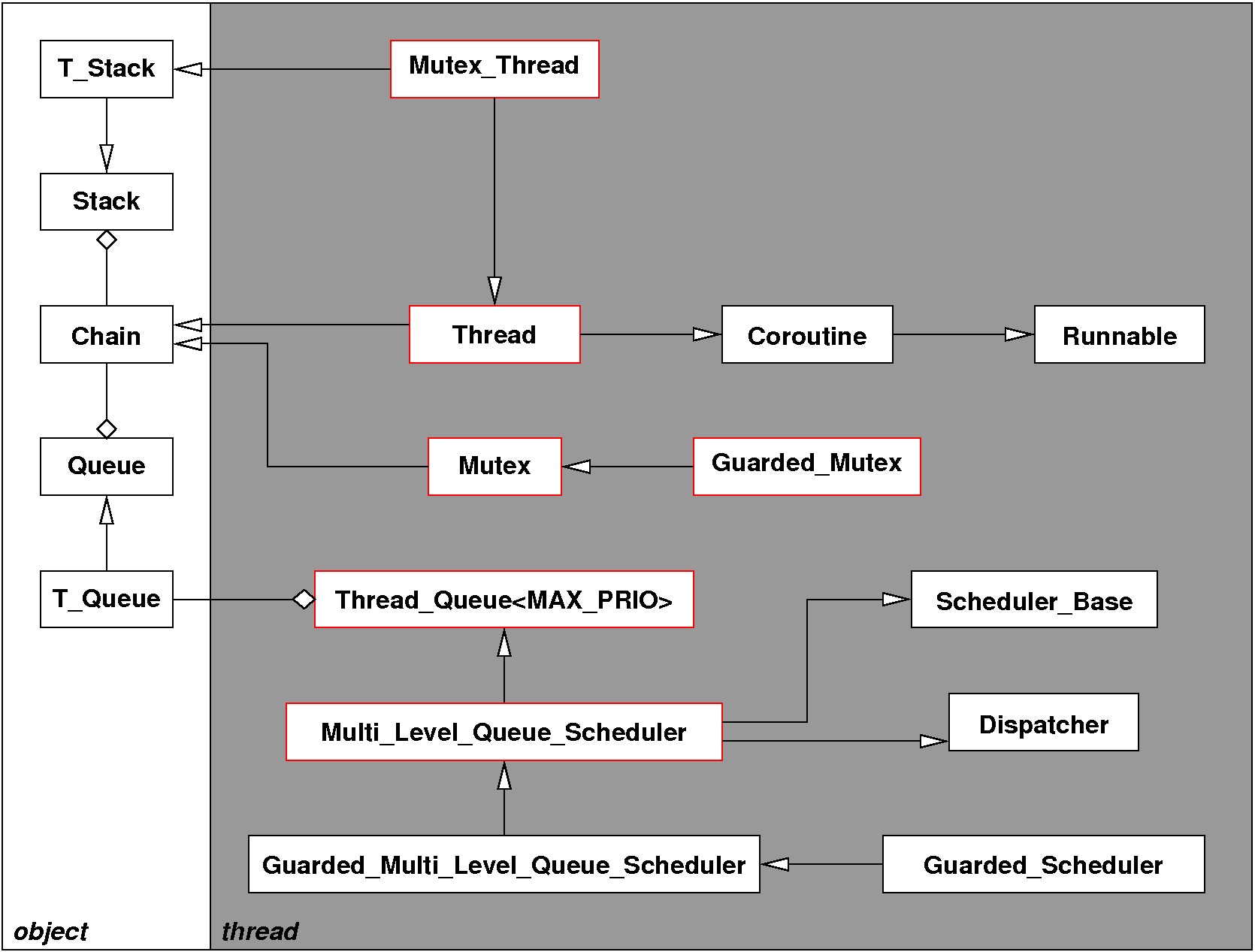
Konkret sind zur Lösung der Aufgabe die folgenden, rot eingerahmten Klassen zu implementieren bzw. zu erweitern:
Mutex und Guarded_Mutex
Die Implementierung des Mutex bzw. der Benutzerschnittstelle des Mutex.
Thread und Mutex_Thread
Durch das Belegen eines Mutex kann sich die Priorität eines
Mutex_Thread ändern, normale Thread-Objekte dürfen keinen Mutex
belegen. Die Methode get_priority() ist daher als virtuelle
Methode zu implementieren, während für normale Thread-Objekte
einfach die statisch zugeordnete Priorität zurückgeliefert werden
kann, muss für einen Mutex_Thread überprüft werden, welche
Mutexes dieser gerade belegt. Für die Bestimmung der aktuellen
Rückfallpriorität muss der Mutex_Thread einen Stapel aller belegten
Mutexes verwalten. Um Threads, die keinen Mutex belegen wollen, nicht mit
diesem Overhead zu belasten, dürfen nur Mutex_Threads Mutexes
belegen. Warum ist ein socher Stapel notwendig? - Ein Mutex_Thread kann auch
mehrere Mutexes belegen, die auch unterschiedliche Prioritätsobergenzen
besitzen. Gibt der Faden zunächst nur einen Mutex frei, fällt seine
Priorität auf die Prioritätsobergrenze des Mutex zurück, den
der Faden noch belegt, nicht auf die statisch zugeordnete Priorität des
Fadens. Der Mutex, der noch belegt ist, muss also zugreifbar sein, sonst
wäre dessen Prioritätsobergrenze auch nicht mehr zugreifbar, zu
diesem Zweck, werden belegte Mutexes in einem Stack verwaltet.
Multi_Level_Queue_Scheduler und Thread_Queue< MAX_PRIO >
Diese beiden Klassen benötigen zusätzliche Methoden, die es
erlauben, die Priorität eines Mutex_Thread auf die
Prioritätsobergrenze des belegten Mutex zu erhöhen, und die beim
Belegen des Mutex aktuelle Priorität, wiederherzustellen, falls der Mutex
wieder freigegeben wird. Sie erhalten daher jeweils zusätzlich die
Methoden void inherit_priority(Mutex_Thread*,ezstubs_uint8) und
void restore_priority(Mutex_Thread*,ezstubs_uint8) (die
Signaturen der Funktionen sind lediglich Vorschläge, diese Funktionen
sind nicht Bestandteil der Benutzerschnittstelle und können daher ohne
Probleme abweichen).